Når data-jakten gir resultater, og du endelig får hendene på et saftig datasett — hva da? Jo, det skal jo inn i en database, eller Excel eller SPSS eller et annet verktøy, for analyse. Om målet er å lage en webapplikasjon eller skrive en artikkel, så trenger du oversikt over hva datasettet inneholder. Og kanskje en liten datavask?
Vaskehjelp
Google Refine er et open source-program for nettopp dette. Det er hverken en database eller et regnearkprogram — det er litt begge deler. For deg som synes programmering høres skummelt ut, slapp av, dette er ikke nødvendigvis mer komplisert enn Excel. Det likner til og med litt. For deg som synes Excel høres litt uproft og begrenset ut, slapp av, du kan scripte (Jython, Clojure og et eget GEL, gridworks expression language) og eksportere til flere fornuftige formater. Programmet lar deg vaske data, få oversikt, gjøre små analyser, og eksportere til videre bruk. Det krever ikke noen spesielle forkunnskaper, og kan fritt tas i bruk av alle. Det kan se ut som om du laster dataene opp til en server, da programmet kjører i nettleseren, men det gjør det heldigvis ikke, og du kan analysere og vaske ditt hemmelige datasett i fred.
Hvordan kommer jeg i gang?
Last ned og installer Google Refine. Så laster du inn et datasett.
For enkelhets skyld bruker jeg videre data om idrettsanlegg postet på data.norge.no. Dette datasettet er en .csv-fil, altså en tekstfil med komma-separerte verdier*. Ved å sjekke filens innhold** kan vi se at det ikke er komma (,) men semikolon (;) som separerer verdiene. Vi ser også at filen ikke har noen rad øverst med forklaring på hva som er i hver kolonne. Dette er ting som Google Refine spør om når du starter et nytt prosjekt, så en liten sjekk av dataene i din favoritt tekst-editor er påkrevd.
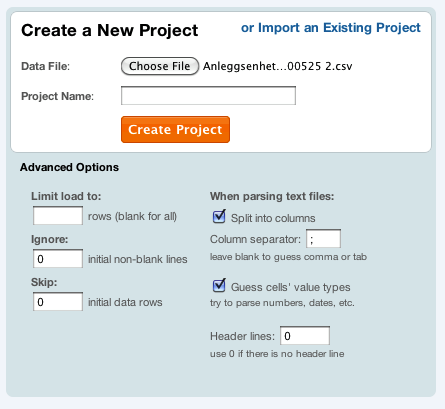
Husk å velge riktig separator, og skriv inn 0 i boksen for header hvis det ikke er noen. Ellers spiser Google Refine denne raden.
Datasettet er vellykket lastet inn i Google Refine — grei skuring
Du og jeg ser forskjell på på Tufte IL og tufte i.l. I en database hvor vi skal hente ut alle idrettsplasser som tilhører dette idrettslaget kan dette tolkes som to ulike ting. Videre har vi problemer som Tufte IL og Tufet IL. Dette er feil som slike datasett ofte inneholder. De er laget av mennesker, og vi mennesker gjør masse slike feil. I Google Refine kan du gjøre bot på andres synder. Via et relativt rikt arsenal av funksjoner kan du rette opp slike feil i alle radene på en gang. Vel, en rettelse av gangen, men på alle radene samtidig. “Finn og erstatt” igjen. Det er også mer avanserte algoritmer for å finne og gruppere slike tekstlige likheter. Programmet inneholder en hel del ulike måter å vaske dataene på, både for tekst og tall.
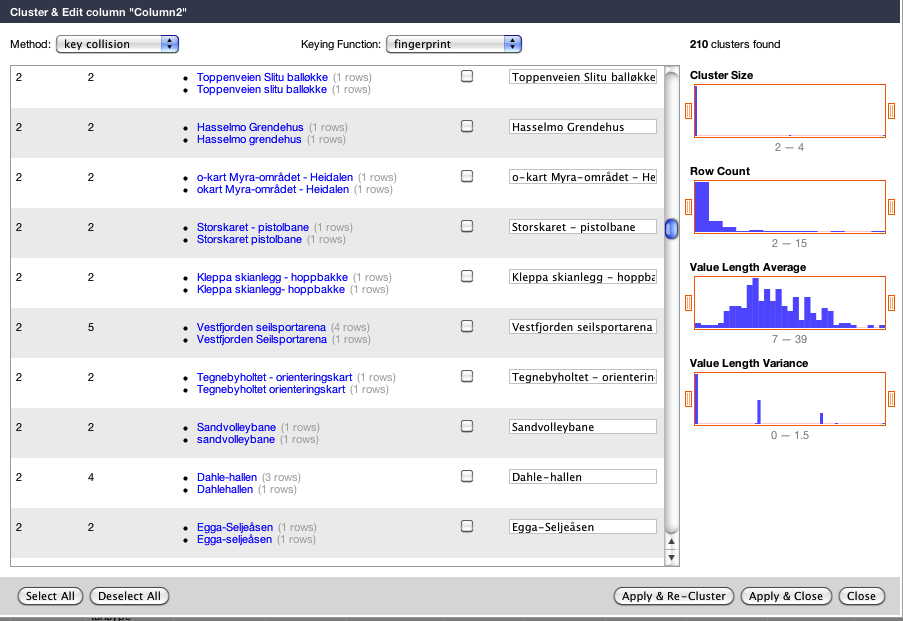
Google Refine har flere algoritmer for å finne celler som inneholder nesten det samme, og lar deg erstatte alle feilstavinger og andre språklige avvik.
NB: Vær varsom med de mer avanserte tekst-funksjonene hvis du ikke er helt sikker på hva som foregår. Det er lite forskjell på Tufte IL ogtufte L.i, men mer alvorlig hvis du slår sammen Åsen IL med Tåsen IL eller Os kommune med Ås kommune. Programmet vil foreslå slike likheter som potensielle kandidater til sammenslåing også, det vil neppe folk på Tåsen, Åsen, Os og Ås bli glade for.
Inspeksjon: Minianalyse med facets
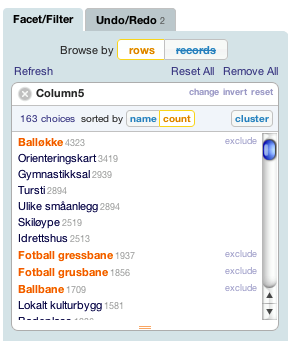
Videre kan du lage “facets” eller “aspekter”, som er widgets som lar deg trekke ut subset av datasettet. Slik kan du raskt skaffe deg oversikt. For eksempel tok det to minutter å finne ut av datasettet om idrettsanlegg har 3401 skyteanlegg, 101 akebakker, 33 minigolfbaner og 17 turnanlegg. For en del oppgaver vil dette være nok. Disse “fasettene” er enkelt og greit spørringer i databasen, og trekker ut deler av dataene basert på ulike parametre.
For eksempel kan du lett hente ut alle fotballanlegg, alle anlegg som eies privat eller anlegg som som ikke er eiet av stat/kommune/fylkeskommune. Videre viser det seg fort at de 51695 anleggene som finnes stort sett er strukturert på et tilstrekkelig konsistent vis til at det vil kunne brukes videre. Koordinater for lokasjon finnes også, og med en runde i et GIS-verktøy vil vi kunne hente ut enheter etter lokasjon.
I illustrasjonen over er anleggstyper som har med fotball valgt, det er enkelt å eksportere kun disse til en fotball-app, hvis noen entusiaster vil lage en.
Det er mange og mer avanserte funksjoner i Google Refine, du finner dem beskrevet på prosjektsiden til programmet på code.google.com/p/google-refine. Det finnes også noen video-bruksanvisninger som gir et greit innblikk: video1, video2, video3.
Eksport gjøres til et utvalg formater, et du kan bruke finner du nok.
Må vi vaske?
Som Fakta først-rapporten viser, er kvalitet et av hindrene (av flere) som gjør at dataholdere i offentlig sektor treger med å dele data. Videre har f.eks. Avinor erfaringer med at å åpne opp data kan hjelpe til å heve kvaliteten på dem. Dette innebærer at noen som ikke er Avinor har gitt tilbakemelding. Det er bra for begge parter. Så ja, vi må vaske, i alle fall i starten. Heldigvis er ikke dette nødvendigvis en veldig vanskelig jobb, og med verktøy som Google Refine kan det også bli en ganske effektiv prosess. Hvis vi ønsker å gjenbruke data, må vi også sette oss ned for å forstå dataene, vaske og pusse dem, og dernest sette i gang viderebruk. Det er rådata som er mest interessant å gjenbruke, og rådata er nettopp det, rå.
Lykke til med datavasken!
PS: Det er selvsagt mange ulike metoder for datavask, denne teksten omtaler kun én. Grunnen til at Google Refine blir trukket fram er den uvanlige kombinasjonen av database, regneark og scripting. Det er også gratis og open source, og gjør just datavask-jobben bedre enn alle andre verktøy jeg har kjennskap til.
* Jeg fant at dette datasettet har noen rariteter, f.eks. er noen rader innkapslet i gåsetegn (“), som gjør at det blir noe kluss. Find & replace slike tegn med ingenting () og lagre. Så vidt jeg ser skaper dette ikke noen videre problemer for dataene. Denne “find & replace”-prosessen gjør du i en egnet tekstbehandler
** Du kan sjekke filen i f.eks. Notepad, Textedit eller i et annet tekstbehandlingsverktøy (textMate for Mac er min favoritt, Notepad++ for windows er etter sigende også fine saker, det finnes mye bra open source-ting for Linux).

[…] This post was mentioned on Twitter by Vox Publica, Offentlige data. Offentlige data said: Raffinering av data: Smart verktøy hjelper deg med å få oversikt over datasettet, “vaske” det og gjøre det klart f… http://bit.ly/bjqocv […]