Prosjektet Fakta først arbeider med å kartlegge offentlige datakilder som bl.a. kan brukes til journalistiske formål. Første innlegg i bloggen fikk overskriften Data er fakta vi kan bruke. Lesere har oppfordret oss til å ta et skritt tilbake og forklare hvordan det rent teknisk går til når en virksomhet frigir data for viderebruk av andre. Hva kreves av tilrettelegging, hvilke formater er å foretrekke — det er noen av spørsmålene vi forsøker å svare på her.
I informasjonsvitenskapen beskrives data som “bærer av informasjon”, “en samling symboler som når de settes sammen etter bestemte regler, kan gi informasjon”[1]. Før vi har lagt på disse reglene omtales ofte datasettene som “rådata”. Det er så reglene vi bruker til å behandle rådataene som avgjør hvilken informasjon vi kan få ut av dem. Å dele data åpner for alternative måter å behandle dataene på, alternative regelsett til å oversette rådata til informasjon. Hvis dette gjøres på metodisk holdbare måter blir dataene omgjort til informasjon vi kan bruke. I beste fall hjelper dette oss til å basere vår forståelse av verden på fakta.
Hva skal til for at data skal kunne gjenbrukes?
Enkelt sagt bør dataene være plattformuavhengige, maskinlesbare og ha en tydelig struktur. Det betyr at de kan brukes på en hvilken som helst datamaskin, og må være mulig å håndtere med programkode uten at et menneskelig øye og tolkning må til for å forstå innholdet. Struktur og metadata (data om data) hjelper oss å gjøre dette mulig.
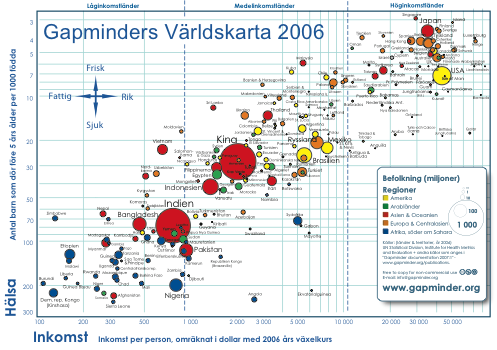
Professor i internasjonal helse, Hans Rosling, har gjort seg til verdenskjent forkjemper for å frigi offentlige statistikker verden over. Her illustrert ved et skjermbilde fra hans prosjekt Gapminders programvare Trendalyzer som her viser verdens land fordelt etter levealder og inntekt.
Hvilke data?
Intensjonen bak frislipp av offentlige data er ikke bare målet om gjennomsiktighet, men også innovasjon. Hvilke produkter og tjenester som bygges på grunnlag av data som deles aner vi lite om før dataene er tilgjengelig. Når data som tidligere har vært skjult bak kommunegrå vegger åpnes, åpnes også et potensial for friske øyne til å se nye måter å skrive kode som omdanner rådata til informasjon.
Litt enkelt: hvis frislipp ikke innebærer betydelig ulempe for andre (personvern, konkurransehensyn, med mer) og er betalt av skattebetalerne, så bør dataene frislippes.
Hva slags format skal jeg dele i?
Viktigst av alt, formater likesinnede kan bruke. Er du usikker, del det du tror andre kan bruke. Men dette er ikke alltid et enkelt spørsmål å besvare, det kommer i stor grad an på hva slags data du har.
Det er vanskelig å kategorisere datakilder, offentlige så vel som andre. Hvor ofte datasettene endres og hvor store de er kan gi en indikasjon på hvordan de bør deles.
Enkelte datasett er små og oppdateres sjeldent, slik som navn på fylker og kommuner, postnummer, flyplasser, politi‑, helse og sosialdistrikt, osv. Slike datasett kan gjerne være tilgjengelig som flate filer. Med “flate filer” menes datafiler som er strippet for programspesifikke koder og notasjoner, slik at dataene kan leses av ulik programvare. Erik Bolstad deler forbilledlig postnummerregisteret etter en opprydningsdugnad i sommer.
Data som sjeldent eller aldri blir oppdatert bør deles åpent på nett, slik at søkemotorer kan hjelpe folk å finne ut at disse dataene eksisterer. Dette trenger ikke være mer komplisert enn å legge filene med beskrivelse tilgjengelig på nett.
Dette er på ingen måte noen «best practice» for deling av data, men det er en metode med lav terskel for å komme i gang. Flate filer krever at de som skal gjenbruke dataene må reorganisere dataenes logiske struktur, en potensielt tidkrevende og vanskelig oppgave, som kan resultere i uriktige tolkninger av dataene.
Data som ofte oppdateres kan også legges på nett som filer, men dette skaper fort mye manuelt arbeid for alle parter. Med store datasett likeså.
Gi oss et API!
Et API er et programmeringsgrensesnitt som muliggjør kommunikasjon mellom programvare. I mange tilfeller vil det som er mest aktuelt være et web-API, altså et grensesnitt en programmerer kan nå over http (protokollen weben er bygget på).
Litt enkelt igjen: når du peker nettleseren din til www.uib.no, så svarer webserveren som denne websiden er lagret på med å servere deg html som nettleseren viser som en webside. Den kunne (og kan) likeledes svare med andre formater, som XML, JSON, RSS, kommaseparerte verdier, SVG, et bilde, osv. “Svaret”, altså de dataene som sendes tilbake etter at et kall er utført, kan behandles videre i den programvaren som utførte kallet. Ved å definere et sett med regler for hvilke ressurser som kan nås med ulike metoder og parametre, kan data raskt, presist og enkelt utveksles.
Når data deles på denne måten kalles tjenesten for en web service, som er et av temaene vi legger i ideen om den semantiske veven [2].
Yr.no har fått mye fortjent kudos for sitt frislipp av værdata, og ved å lese dokumentasjonen deres får vi et inntrykk av hvordan dette kan gjøres. NRK grubler på hvordan de kan gjøre noe liknende, det samme gjør SSB.no under prosjektnavnet Nye ssb.no (se eget blogginnlegg om SSBs nettplaner).
Dokumentasjon er et nøkkelord her. For at en slik tjeneste skal være virkelig nyttig bør dokumentasjonen være brukervennlig. Google kan trekkes fram som et godt eksempel. Deres tjenester som har et offentlig API er som regel dokumentert i detalj og med gode eksempler med kode. Google Maps API er et eksempel for kart. Se også Flickr for bilder, Last.fm for nettsamfunn/musikkdata, osv. Nye tjenester som dukker opp og blir populære på nett har ofte et dokumentert API som gjør at data lett kan gjenbrukes.
RSS er din venn. Uansett hva slags informasjonskanal du deler på nett er det noen som er interessert i å vite når du publiserer noe nytt. Hvis du sitter på data som uregelmessig produseres og er uforutsigbare av natur (kalenderdata den ene dagen, informasjonsskriv, kart eller bilder den neste) så er det bedre at vi får vite at noe nytt er på gang framfor å måtte tråle weben kontinuerlig.
Men viktigst: Vi må vite hva vi ser etter
Vi trenger også en norsk utgave av data.gov, en samlet oversikt over rådata på ett sted. Danskene har det allerede i digitaliser.dk, og en britisk versjon er rett rundt hjørnet. Kartleggingsprosjektet vi informerer om på denne bloggen har begynt på en slik oversikt. Det er i det hele tatt god grunn til å tro at det bare er et spørsmål om tid før et norsk data.gov kommer. Forskningsprosjektet Semicolon har slike planer, som det fremgår her. Det er også private initiativer; nylig har Sondre Bjellås startet wikien datakilder.no.
Som Nick Diakopoulos påpeker bør en slik sentral samling av datakilder inneholde automatisk sporing (f.eks. ved trackbacks) av prosjekter som bygger på data herfra. Slik kan vi bygge på hverandres erfaringer og kode, og unngå dobbeltarbeid.
Det største problemet for kartlegging av offentlige data sett fra en prosuments perspektiv, er at vi ikke vet hva vi ser etter. Først når vi vet hvilke rådata som finnes, kan vi begynne å gruble over hvordan disse dataene kan omformes til samfunnsnyttig informasjon.
Referanser
- Trond R. Braadland, Innføring i informasjonsbehandling (Fagbokforl., 2002), books.google.com.
- Thomas B. Passin, Explorer’s Guide to the Semantic Web (Manning Publications, 2004).

[…] Kan mine data gjenbrukes? — […]